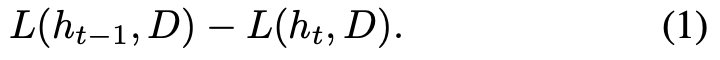Fig 1. Bounty-based Incentive Mechanism. h is used to denote a machine learning model and D for a dataset. The smart contract clipped the loss function L(h, D) to the range [0, 1].
最后,我们必须将这一机制扩展到赏金 B。J.D. Abernethy 提出的方案要求所有参与者质押 B,这在实际操作中不可行。因此,采用每次迭代 B 次的方式来实现。每次迭代中,参与者质押一些代币并获得奖励。如果由于损失而无法再质押代币,参与者将退出。尽管这有些复杂,但可以认为,ht 表现越好,参与者 t 得到的奖励就越多,因此我们认为参与的激励与目标是高度一致的。