Data Collection
In AI, gathering data is a big hurdle slowing down progress. A lot of machine learning projects work is about getting the data ready. This includes collecting, cleaning, analyzing, showing it visually, and preparing features. Collecting data is the toughest of all these steps for a few reasons.
First, when machine learning is applied to new areas, there often isn't enough data to train the machines. Older fields like translating languages or recognizing objects have a ton of data collected over the years, but new areas don't have this advantage.
Also, with deep learning becoming more popular, the need for data has gone up. In traditional machine learning, much effort goes into feature engineering, where you need to know the field well to pick and create features for training. Deep learning makes this easier by figuring out features independently, which means less work in preparing data. But, this ease comes with a trade-off: deep learning usually needs more data to work well. So, finding effective and scalable ways to collect data is now more critical than ever, especially for big language models (LLMs).
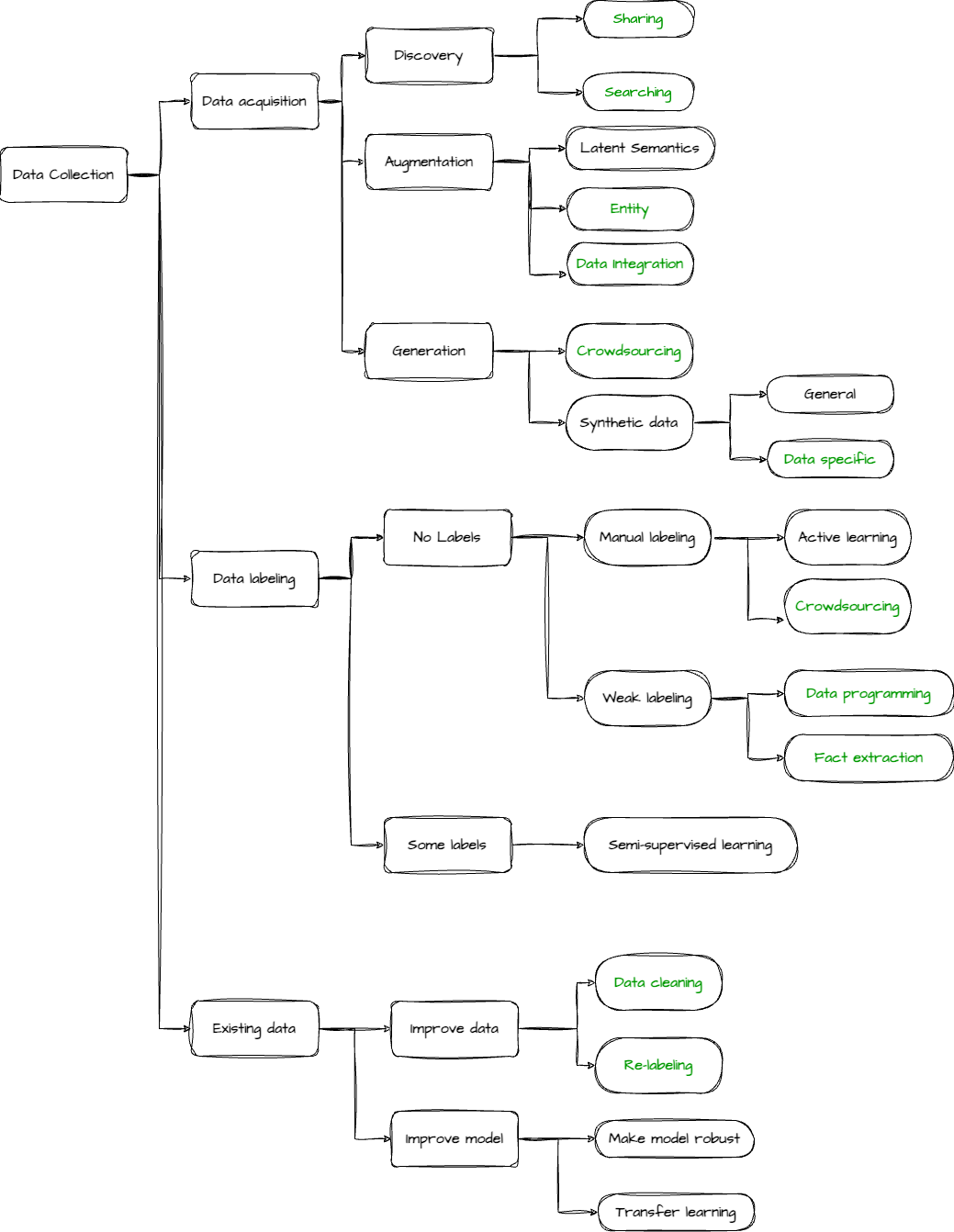
Fig.1 shows a high-level landscape of data collection for machine learning. The sub-topics that the community can decentrally contribute are highlighted using green text.
Anyone can help the entire DIN network collect on-chain and off-chain data through the two dApps in the ecosystem, Analytix and xData.
The network rewards data collection nodes based on the data quality (this quality assessment standard is automatically determined by the network, that is, with the help of the validator node).
The validator node is permissionless, which ensures that the more people participate in network construction, the more robust the entire network will be.
最后更新于